
发布日期:2026-05-07 09:58:43
4月下旬,OpenAI 正式发布了 GPT-5.5。
这一次升级,不只是模型或回答质量的简单提升,更重要的是:ChatGPT 正在从“对话工具”,进一步走向“智能体工作系统”。
相比上一代 GPT-5.4,GPT-5.5 在复杂任务处理、编程能力、工具调用、智能体执行和专业生产力场景中,都有了更明显的增强。
对于开发者、企业用户、内容团队,以及正在关注 GEO 的品牌来说,这可能是一次值得重点关注的模型升级。

整体来看,GPT-5.5 的升级主要集中在五个方向:
· 复杂任务处理能力更强:不只是回答问题,而是能够更好地规划任务、拆解步骤、调用工具,并在执行过程中进行调整。
· 编程能力进一步提升:在代码编写、调试、测试、重构等场景中,工程可用性更强。
· 工具使用和智能体能力增强:能够更准确地判断什么时候需要搜索、什么时候需要调用工具,以及如何在多个工具之间切换。
· 效率提升:能力更强,在部分实际任务中,GPT-5.5 能够用更少的 token 完成任务。
· 安全防护进一步加强:GPT-5.5 在发布前经过了更严格的安全测试,尤其针对高风险领域进行了评估。
1、更强的复杂任务处理能力
GPT-5.5 最大的变化之一,是它对复杂任务的处理能力更强。
过去,用户更多把 ChatGPT 当作一个问答助手使用。
但 GPT-5.5 更像是一个可以参与工作流的智能体:它能够理解任务目标,拆解执行路径,并在多个步骤中持续推进任务。
比如在软件开发场景中,GPT-5.5 不仅可以写代码,还可以:
· 分析需求
· 设计实现方案
· 编写代码
· 调试错误
· 执行测试
· 验证结果
· 给出修改建议
这意味着,GPT-5.5 不再只是“回答得更好”,而是更接近“能把事情做完”。
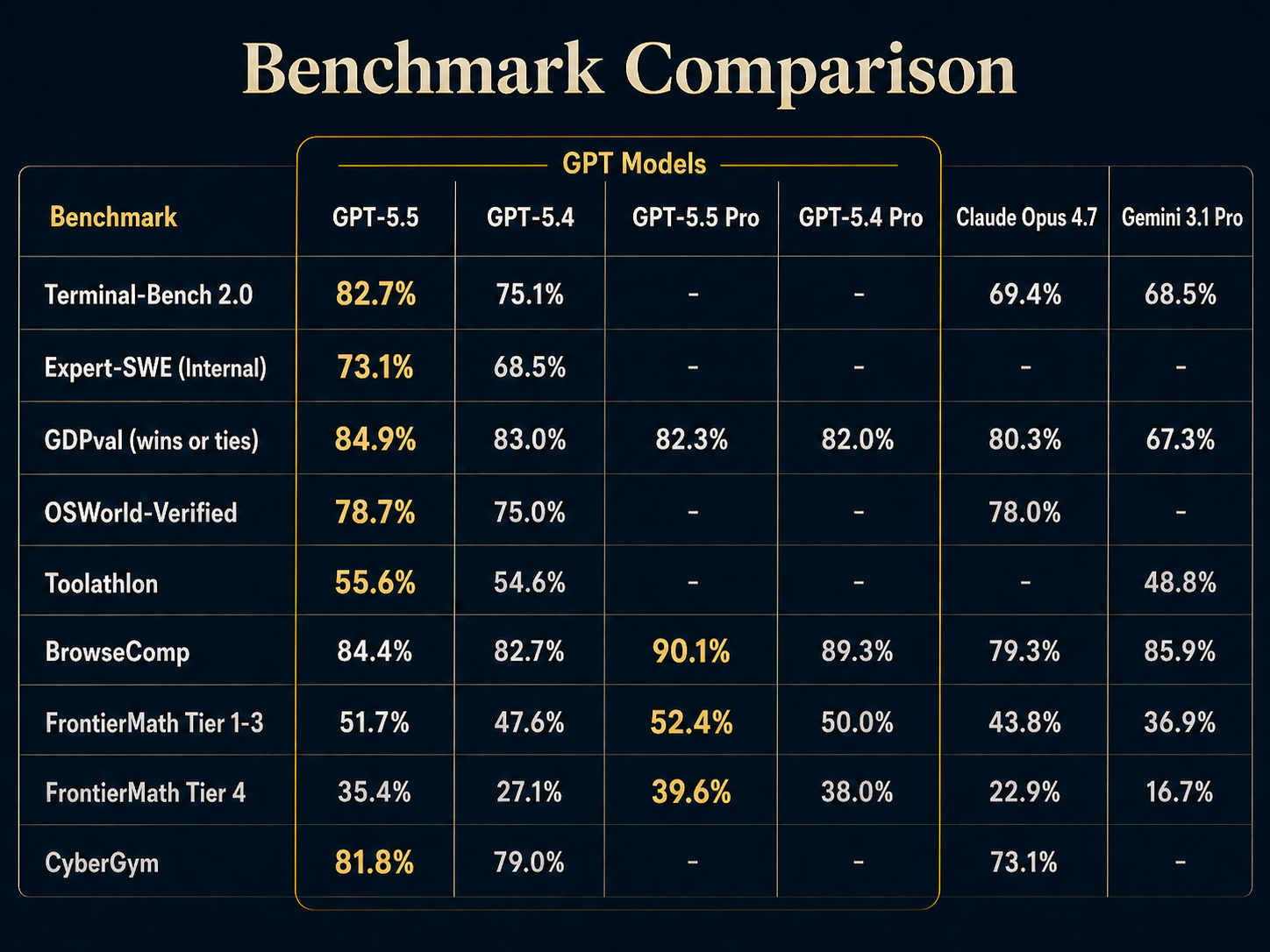
核心能力对比
2、编程能力大幅提升
在编程能力方面,GPT-5.5 的表现也更加突出。尤其是在复杂工程任务和长周期开发任务中,它比 GPT-5.4 更适合处理完整的工程流程。
从官方评测看,GPT-5.5 在 Terminal-Bench 2.0 上从 GPT-5.4 的 75.1% 提升至 82.7%,提升较明显;在 SWE-Bench Pro Public 上从 57.7% 提升至 58.6%,属于小幅提升;在内部 Expert-SWE 长周期工程任务中也从 68.5% 提升至 73.1%。
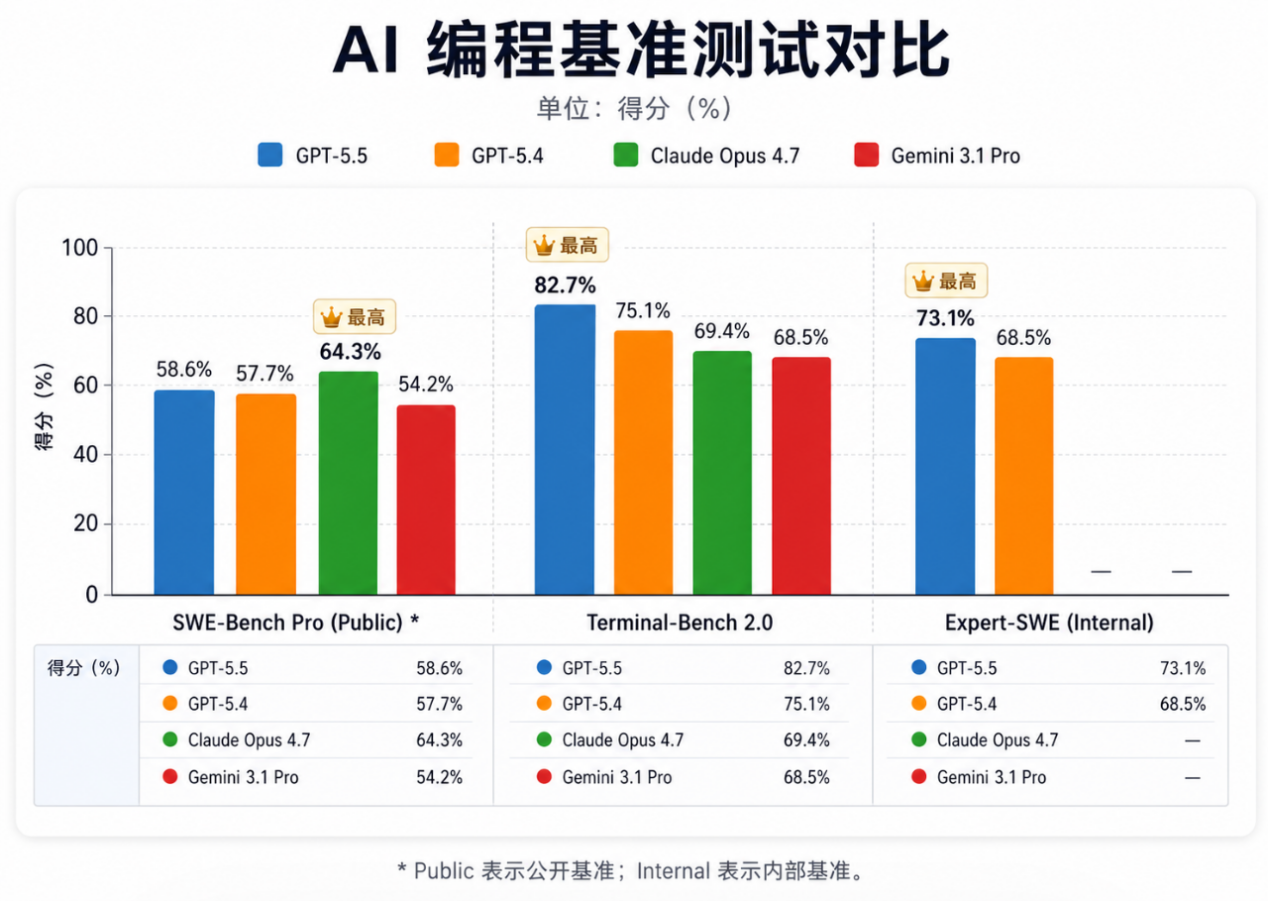
对于开发者来说,这种提升的意义在于:GPT-5.5 更适合参与真实工程项目,而不只是完成单点代码片段。
它可以承担从实现、重构到调试、测试的完整流程,尤其适合复杂项目中的辅助开发和智能体式工程任务。
3、工具使用与智能体能力更强
GPT-5.5 另一个重要变化,是工具使用能力的增强。
它可以更好地理解:什么时候需要搜索?什么时候需要调用工具?什么时候需要读取文件?什么时候需要分析图片?什么时候需要处理数据?
这让 GPT-5.5 在“知识工作”场景中的表现更加稳定。比如在复杂客服流程、职业知识工作、数据处理、内容分析等任务中,GPT-5.5 可以更像一个执行型助手,而不是单纯的文本生成模型。
这说明 GPT-5.5 在处理更复杂、更长链路、更接近真实业务场景的任务时,已经具备了更高的可用性。

4、速度与效率同步提升
能力增强之后,很多人会关心一个问题:GPT-5.5 会不会更慢?会不会更贵?
官方更强调 GPT-5.5 的 token 效率提升,而不是简单承诺“同等速度”。在 Codex 中,OpenAI 表示 GPT-5.5 对多数用户能用更少 token 产出更好结果;同时,Codex Fast mode 可将 token 生成速度提升约 1.5 倍,但成本为标准模式的 2.5 倍。
也就是说,它虽然单价更高,但在某些复杂任务中,可能会因为执行效率提升而降低部分 token 消耗。
从整体成本来看,GPT-5.5 仍然更适合高难度、高价值的任务,而不是简单问答场景。
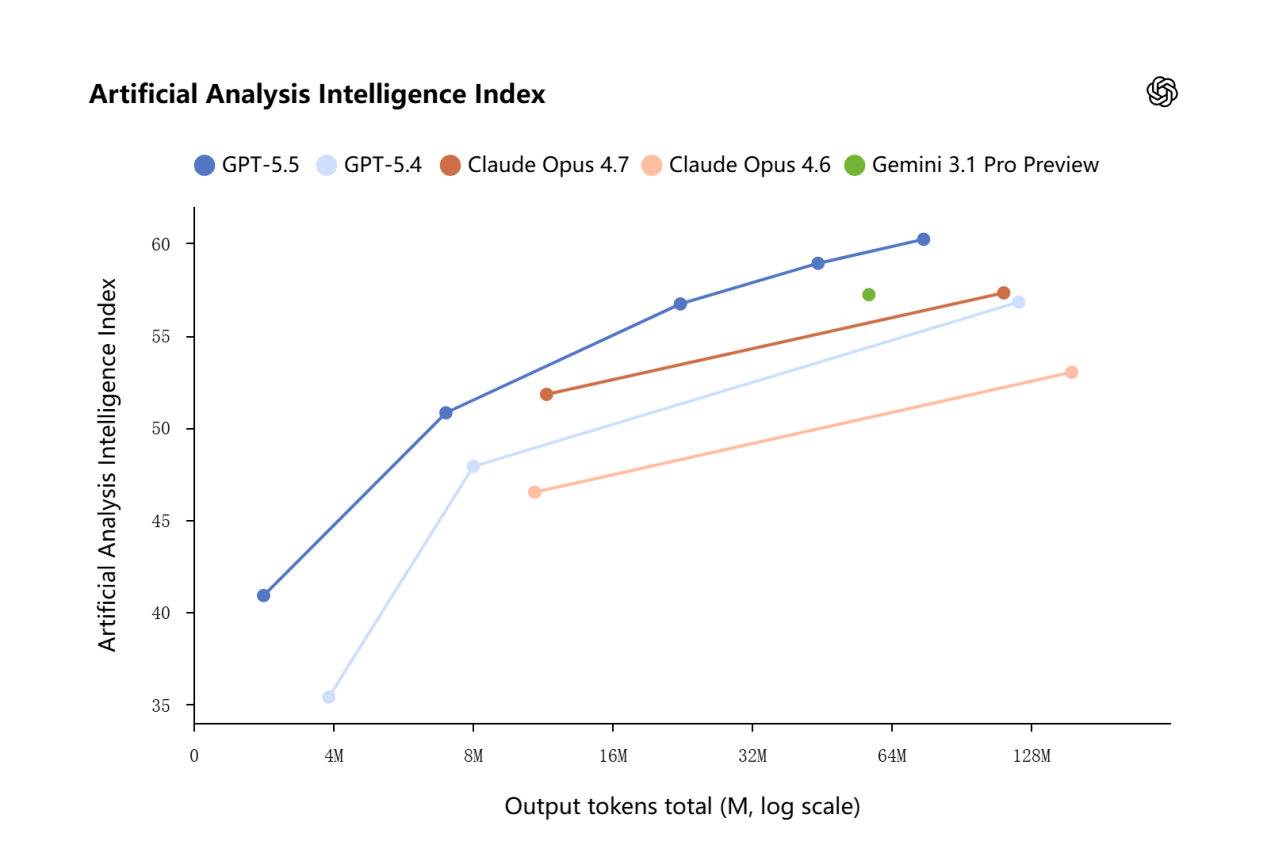
图源:公开资料整理
5、安全防护进一步加强
GPT-5.5 也强化了安全防护能力。尤其是在网络安全、敏感数据处理、高风险任务执行等领域,OpenAI 表示已经进行了更全面的安全测试。
其中,在 CyberGym 测试中,GPT-5.5 的得分高于 GPT-5.4。
|
测试项目 |
GPT-5.5 |
GPT-5.4 |
|
CyberGym |
81.8% |
79.0% |
|
Capture-the-Flags challenge tasks(Internal) |
88.1% |
83.7% |
这意味着,GPT-5.5 在面对更复杂、更高风险的任务时,不只是能力提升,也在安全边界上进行了进一步优化。
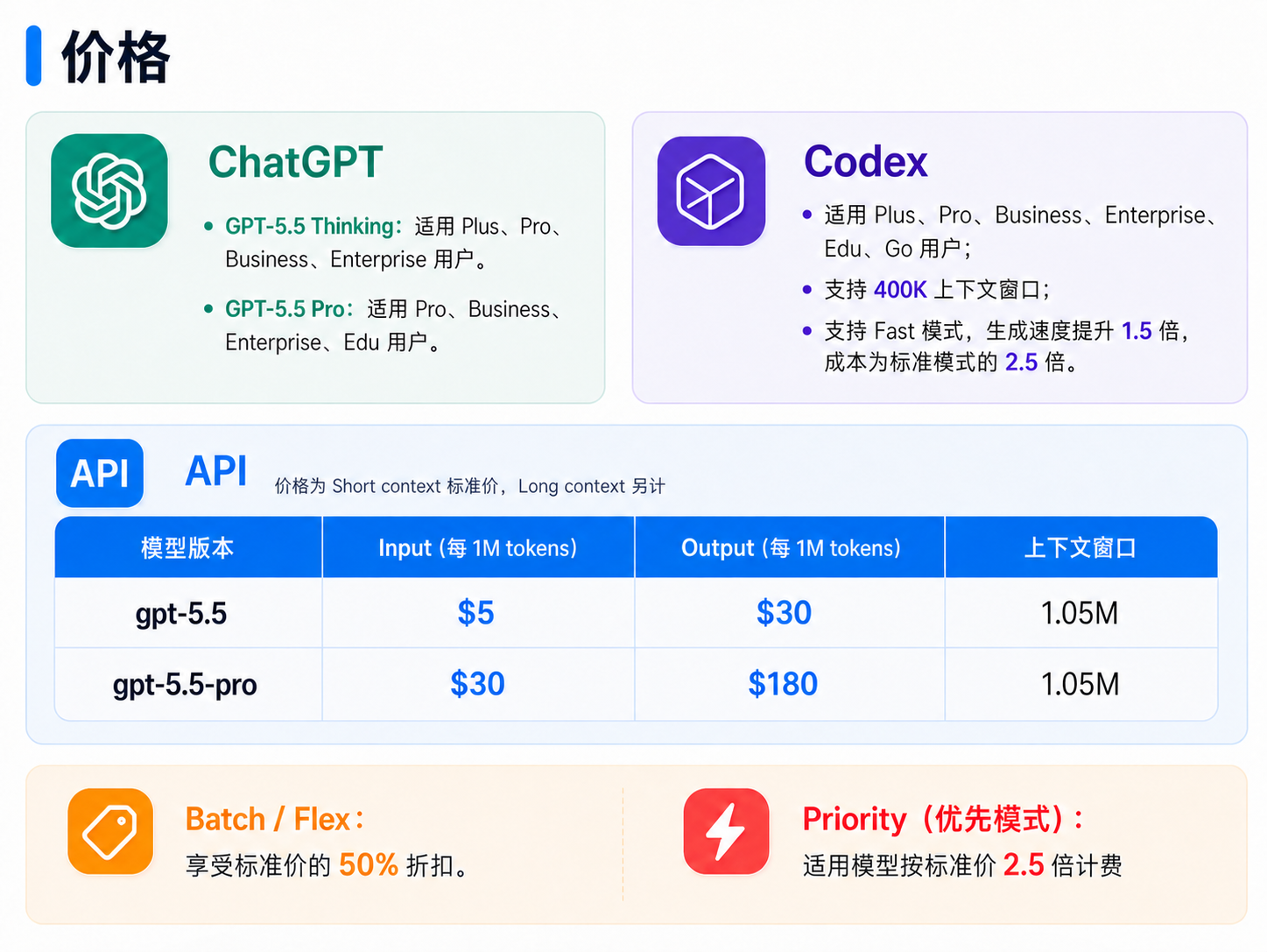
ChatGPT
· GPT-5.5 Thinking:适用 Plus、Pro、Business、Enterprise 用户
· GPT-5.5 Pro:适用 Pro、Business、Enterprise 用户
Codex
· 适用范围包括 Plus、Pro、Business、Enterprise、Edu、Go
· 支持 400K 上下文窗口,并支持 Fast 模式
· Fast 模式生成速度提升约 1.5 倍,成本为标准模式的 2.5 倍
API 价格
|
模型版本 |
Input(每 1M tokens) |
Output(每 1M tokens) |
上下文窗口 |
|
gpt-5.5 |
$5 |
$30 |
1M |
|
gpt-5.5-pro |
$30 |
$180 |
- |
Batch / Flex:标准价的 50%
Priority 优先模式:标准价的 2.5 倍
与 GPT-5.4 相比,GPT-5.5 的价格翻倍,但其效率更高,实际消耗的 token 更少,综合算下来,总价是有所上升,但对于需要高难度任务执行的用户来说,仍然可以接受。
GPT-5.5 的发布,对 GEO 来说也有重要影响。它不只是模型能力变强,更意味着 AI 的推荐逻辑和答案组织方式正在发生变化。
我们对多个商品推荐类prompt进行不同模型监测中发现,相比 GPT-5.4,GPT-5.5 的回答更标准化、更列表化,也更倾向于按照使用场景、产品类型和用户需求进行分类推荐。
也就是说,模型不再只是给出一个“最佳答案”。它更像一个结构化导购系统:先覆盖多个主流选择,再根据不同场景解释每个产品适合的人群。
在 GPT-5.5 的回答逻辑下,品牌在 AI 结果中的竞争会变得更加精细。
过去,很多品牌做 GEO 时,重点关注的是:我的品牌有没有被 AI 提到?
但在 GPT-5.5 之后,这个问题可能还不够。品牌还需要进一步关注:
· 是否进入核心推荐池
· 产品是否出现在靠前位置
· 品牌是否被归入正确的使用场景
· 是否能成为某一类需求下的默认推荐
· 品牌露出是“主推荐”还是“补充选项”
这意味着,GEO 的优化重点正在从“品牌出现”,转向“推荐权重”。
对于企业来说,未来做 GEO,不能只强调产品参数和功能卖点,还需要围绕真实用户需求建立更清晰的语义关联,例如“最适合大多数用户的选择”“某个场景下的最佳选择”“某类人群的优先推荐”等。
同时,GPT-5.5 更重视结构化信息和场景化判断,因此在做 GEO 内容时,需要加强产品对比、应用场景、购买建议、用户痛点、差异化优势等内容建设。
只有让 AI 更容易理解“这个品牌为什么适合某个具体需求”,品牌才更有机会在 AI 推荐结果中获得更靠前的位置。
谁能更清晰地表达产品定位、使用场景和差异化价值,谁就更有机会在 AI 推荐结果中获得更稳定的曝光。
GPT-5.5 是 OpenAI 在提升 ChatGPT 能力方面的一次重要升级。它不仅是一个强大的对话式 AI,更是一个能够在实际工作流中提供持续支持的智能体。对于那些希望将 AI 引入日常工作并提高效率的用户,GPT-5.5 无疑是一个强有力的工具。
想要第一时间掌握Chatgpt的最新动态和官方文档?联系我们,获取我们精心整理的官方资料包,助你快人一步拥抱AI新时代!


扫码关注