
发布日期:2026-05-07 09:53:31
2026 年 4 月下旬,国内大模型圈连续出现两件值得关注的事:DeepSeek 发布 V4 Preview,腾讯混元开源 Hy3 preview。
如果只把它们看成“又一轮模型发布”,这件事并不新鲜。过去一年,大模型更新已经非常高频,用户也习惯了各种模型榜单、参数规模和推理能力测试。但这一次更值得 GEO 从业者关注的地方,不是模型又多会写几段话,而是它们共同指向了一个变化:模型正在从“回答问题的聊天工具”,变成“能读长资料、会比较、能推理、能执行任务的决策系统”。
从行业背景看,DeepSeek V4 Preview 被外部报道放在中美 AI 竞争、国产 AI 基础设施和 Agent 能力提升的框架里讨论。新华社相关报道也提到,同一时期国内多家模型厂商都在更新模型,行业竞争的重点正在从参数规模转向实际任务效果,包括长上下文、推理效率、Agent 能力和幻觉缓解。
这对 GEO 的影响非常直接。传统 SEO 更关心网页能否排在搜索结果前面,而 GEO 面对的是生成式引擎:它会读取多个来源,综合资料,生成答案,并选择性引用某些内容。也就是说,企业内容不只是要“被搜索到”,还要能被模型理解、比较、验证和复述。
所以,DeepSeek V4 和混元 Hy3 preview 的更新,真正值得关注的是:当模型越来越会处理复杂任务,企业内容还停留在关键词堆砌和品牌卖点罗列,就会越来越难进入模型的推荐逻辑。
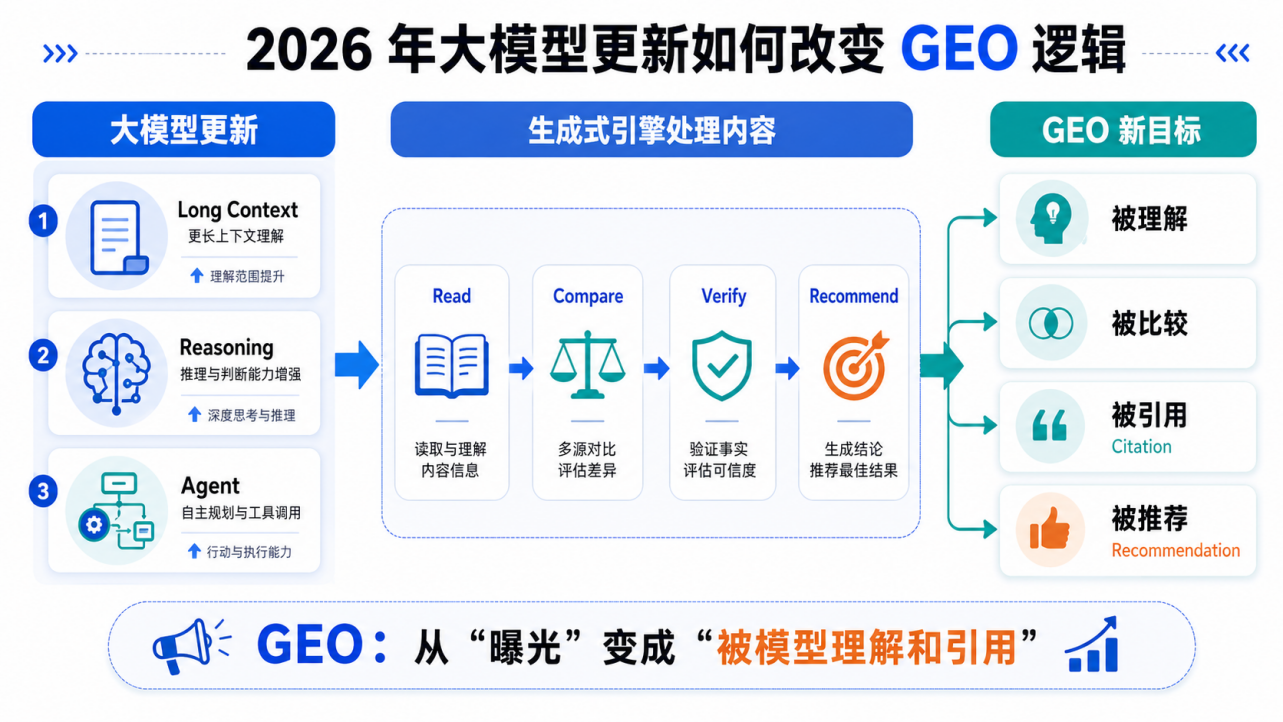
图注:大模型从“回答问题”走向“读取、比较、验证、推荐”,GEO 的目标也从曝光转向理解和引用
DeepSeek V4 Preview 的官方更新里,最核心的是两个版本:DeepSeek-V4-Pro 和 DeepSeek-V4-Flash。
V4-Pro 更像是面向复杂任务的主力模型。官方资料显示,它强调知识、推理、数学、STEM、代码能力,并在 Agentic Coding 等任务上有较强表现。对普通用户来说,这意味着它更擅长处理需要多步判断的问题;对 GEO 来说,这意味着模型不只是看一句标题、一个卖点,而是更可能读取一整段资料,再判断哪些信息值得进入答案。
V4-Flash 则代表另一种方向:更快、更便宜、更适合高频调用。官方资料显示,V4-Flash 在简单 Agent 任务上的表现接近 V4-Pro,同时参数规模和调用成本更低。这个变化很关键,因为生成式搜索和 AI 问答不会永远只使用最强模型。大量轻量搜索、摘要、商品比较、FAQ 问答,可能都会更多依赖这类快速模型。
DeepSeek V4 还有一个对 GEO 非常重要的点:1M 上下文。官方资料提到,DeepSeek V4 使用 token-wise compression 和 DeepSeek Sparse Attention,使长上下文场景下的计算和内存成本下降,并让 1M context 成为官方服务默认能力。
过去,一个模型可能只能读取有限片段,企业内容只要在关键位置放上关键词,可能就有机会被抓到。但长上下文模型可以一次读更多页面、报告、产品资料、FAQ、对比表。内容越多,结构越重要。如果企业内容是一堆松散宣传语,模型读得越多,反而越难抓住重点;如果内容有清晰标题、结论、判断标准、数据依据,它就更容易被模型拆解成可引用的信息单元。
DeepSeek V4 还强调 Agent 能力。官方资料提到,它针对 Agent capabilities 做了优化,并与 Claude Code、OpenClaw、OpenCode 等 Agent 工作流集成。Agent 的意义在于,模型不再只是“回答一次”,而是可以进入更长链路:搜索、读取、比较、判断、执行、再生成结果。
这对 GEO 的要求更高。企业内容要从“网页文案”变成“模型可调用的资料包”。比如一篇产品内容,不仅要有卖点,还要有适用场景、参数解释、对比逻辑、限制条件、FAQ 和来源说明。
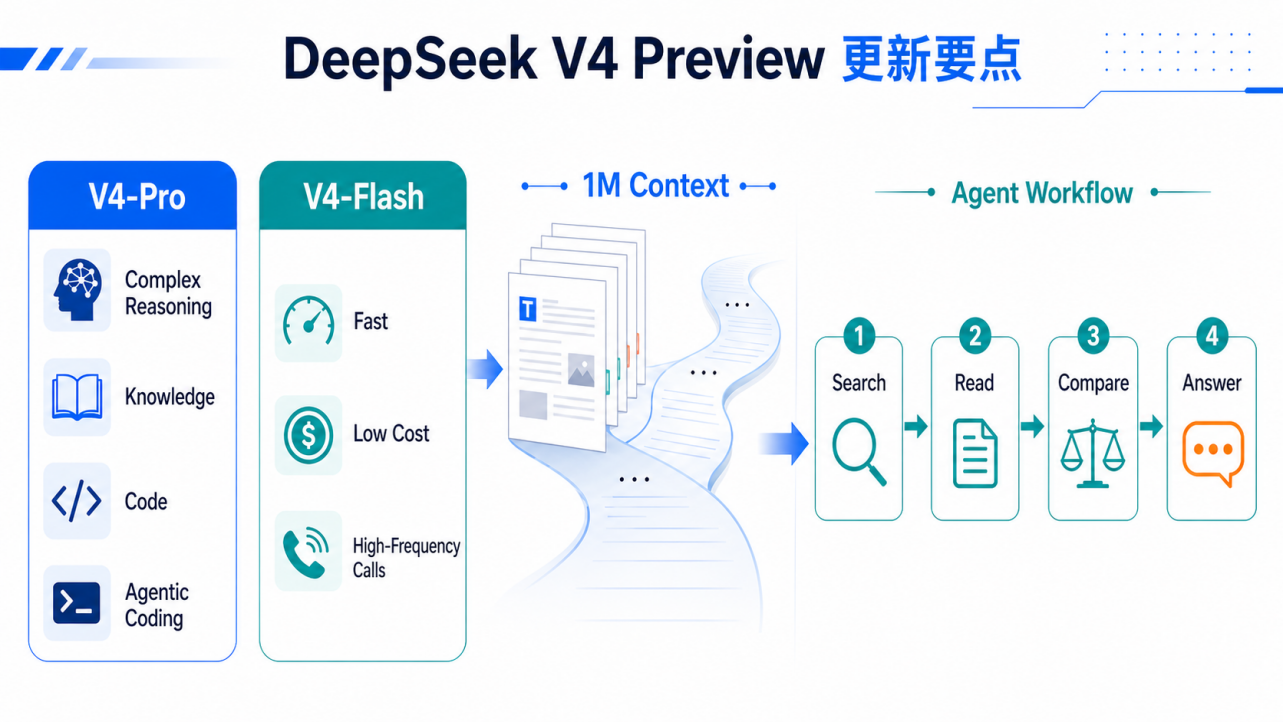
图注:DeepSeek V4 的 GEO 启发,不只是模型变强,而是长上下文、快慢模型组合与 Agent 工作流共同改变内容读取方式
腾讯混元 Hy3 preview 的更新,重点也不只是参数。
官方模型资料显示,Hy3 preview 由 Tencent Hy Team 开发,并于 2026 年 4 月 23 日开源模型权重。它采用 MoE 架构,295B 总参数,21B 激活参数,支持 256K 上下文。官方还特别强调,这是混元团队重建基础设施后训练出的第一个模型,并称其为目前发布过的最强模型。
这些参数本身很重要,但对 GEO 更重要的是它强化了哪些能力。官方资料里反复提到几个关键词:complex reasoning、instruction following、context learning、coding、agent tasks。
翻成中文商业内容语境,就是:模型更会理解复杂背景,更能按用户要求回答,更能从长上下文里学习任务规则,也更能参与 Agent 类任务。
这会改变中文内容被模型处理的方式。用户不再只问“哪个品牌好”,而是会问“预算有限但要办公和学习兼顾,哪个更合适”;也可能问“宝宝肠胃敏感,选奶粉时应该关注哪些因素”。模型如果指令遵循和上下文学习能力更强,就会更倾向于先理解用户的真实约束,再筛选答案。
因此,混元 Hy3 preview 对 GEO 的启发是:中文内容不能只泛泛写品牌优势,而要把真实问题拆开。内容里要说明用户是谁、场景是什么、判断标准是什么、什么情况下适合、什么情况下不适合。
Hy3 preview 还支持 reasoning_effort,可按任务选择 no_think、low、high。复杂问题可以使用更高推理强度,直接回答可使用较低推理强度。对 GEO 来说,这意味着内容需要同时满足两类读取方式:快速模式下能抓住结论,深度推理模式下能找到依据。
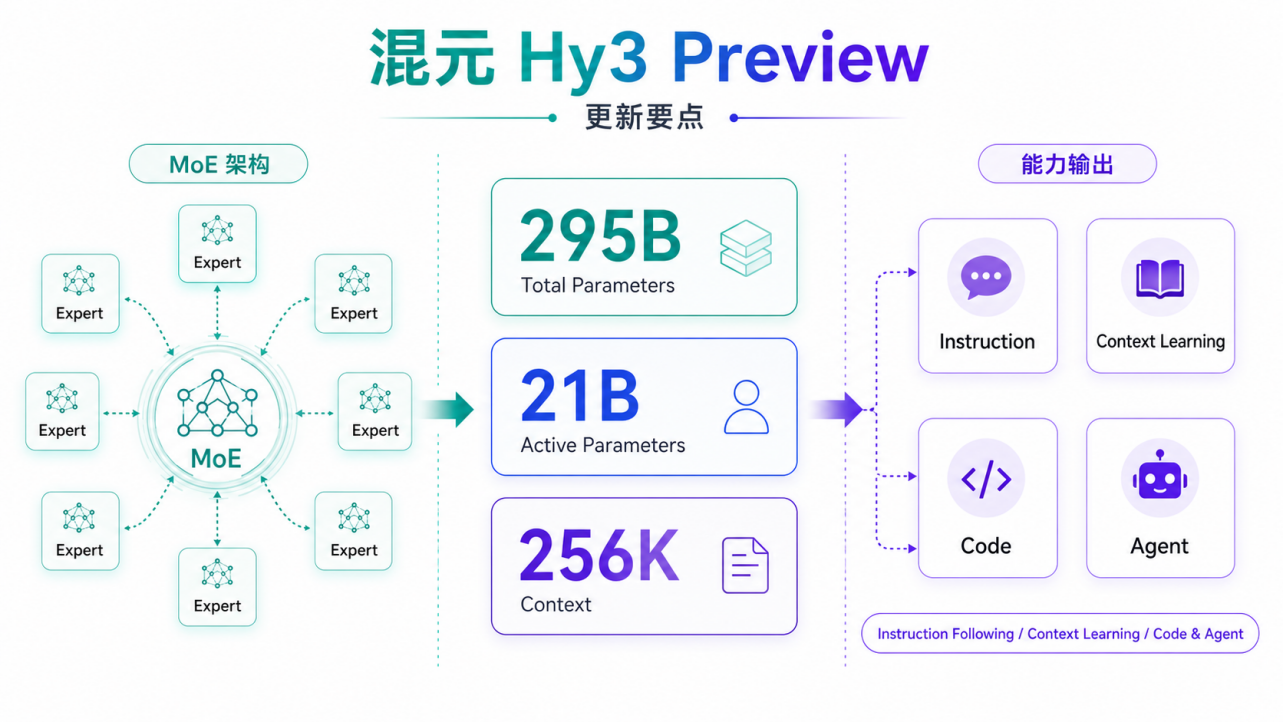
图注:Hy3 preview 的关键不是单一参数规模,而是上下文学习、指令遵循和 Agent 任务能力共同提升
如果把 DeepSeek V4 和混元 Hy3 preview 放在一起看,它们共同指向四个 GEO 变化。
DeepSeek V4 的 1M 上下文和 Hy3 preview 的 256K 上下文,都说明模型能读的资料越来越长。
但这不是说内容越长越好。恰恰相反,长内容越多,模型越需要结构。一个清晰的资料体系,应该有明确标题、段落摘要、对比维度、结论句、FAQ、数据来源和适用边界。
过去企业可能会把很多内容堆在一个页面里,认为这样覆盖关键词更多。但在生成式引擎里,模型不只看关键词,它要理解“这段内容能不能支撑一个回答”。如果内容没有结构,模型很难判断哪句话是结论、哪句话是证据、哪句话只是宣传。
模型推理越强,越不会满足于简单列品牌。
它会更自然地回答:为什么推荐这个?适合什么人?不适合什么人?和其他选择相比优势在哪里?有什么风险或限制?
这意味着 GEO 不再只是争取品牌名出现。品牌名出现只是第一步,更重要的是品牌能否被放进模型的判断框架。比如在 3C 内容里,模型可能会按性能、预算、生态、便携、办公、娱乐来比较;在母婴内容里,模型可能会按年龄阶段、消化吸收、配方特点、适用边界来判断。
企业内容如果只说“高端”“领先”“口碑好”,很难支撑模型给出有理由的推荐。更有效的写法是:给出明确选择标准,并把品牌或产品放进标准里。
Agent 能力增强后,模型可能不只是搜索一次,而是执行一组任务:先搜索,再读取,再比较,再汇总,再生成答案。
在这个过程中,内容是否容易被调用,变得非常重要。
可调用的内容通常有几个特征:结构清楚、事实明确、来源可追溯、对比维度稳定、适用场景清楚、风险边界明确。不可调用的内容,则往往是大段空泛形容词,很难被模型转化成答案。
所以 GEO 的目标要从“让模型看见我”升级成“让模型愿意用我”。这两者差别很大。看见只是曝光,用到才是引用和推荐。
GEO 原始论文把生成式引擎描述为一种新搜索范式:它会综合多个来源,再由模型生成答案。论文提出 GEO 的目的,就是提高内容在生成式引擎回答中的可见性。
后续关于结构化特征的研究进一步指出,文档结构会影响 citation behavior。也就是说,内容的宏观结构、信息分块和重点强调方式,都可能影响生成式引擎是否引用它。
FeatGEO 相关研究也强调,引用行为更受文档级内容属性影响,而不是孤立词汇编辑。换句话说,GEO 不是把关键词换个说法,也不是把语气改得更像 AI 喜欢,而是要优化整篇内容的结构、信息密度、可信度和可引用性。

图注:GEO 的重点从关键词堆砌,转向结构、证据、适用场景和可引用性
前面说的是模型能力和 GEO 技术逻辑。那落到真实行业问答里,模型更新前后到底有什么变化?
这次我们用工作区里的两组行业数据做补充观察:3C 行业对应 DeepSeek 更新前后各 20 条 prompt 问答;奶粉行业对应混元/元宝更新前后各 20 条 prompt 问答。案例模块只使用这份本地表格分析,不额外引入外部案例资料。
3C 数据里,一个很有意思的现象是:DeepSeek 更新后,回答平均字数几乎没有明显增加。更新前平均字数约 2520,更新后约 2544,基本持平。
但品牌提及次数下降了。更新前平均品牌提及次数约 31.85,更新后约 26.15。与此同时,平均引用标记数从 28.15 上升到 31.20,含明确排名词的回答从 5 条上升到 9 条。
这说明更新后的模型不是简单把回答写得更长,也不是把更多品牌堆进去,而是更像在做筛选。它会给出更多依据,更多排名或梯队表达,也会更强调哪些选择更适合当前需求。
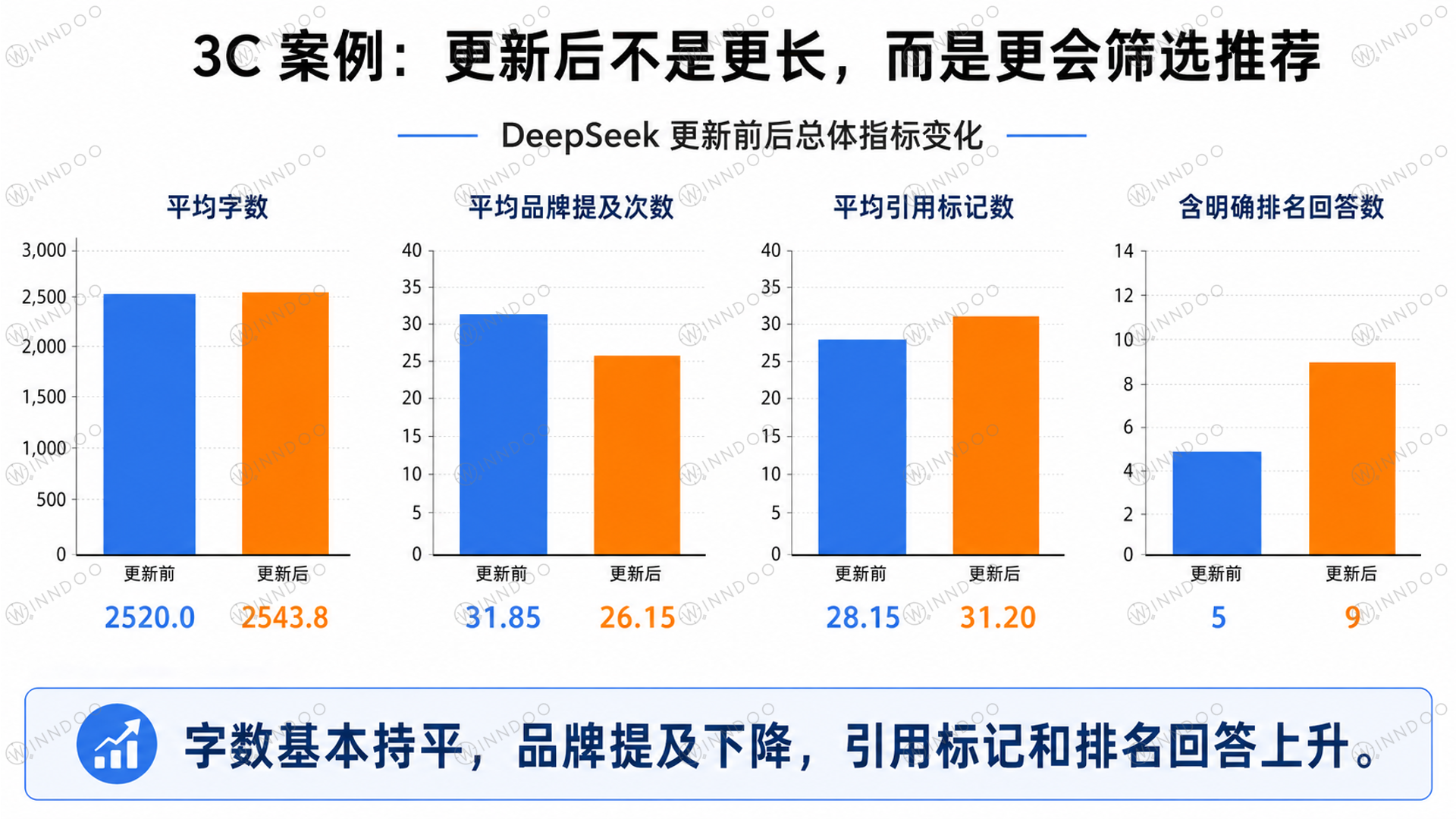
图注:3C 案例中,模型更新后字数基本持平,但品牌提及下降、引用和排名表达上升
从品牌露出看,这种“筛选感”更明显。华为/MatePad、Apple/iPad、小米/Redmi 等高频品牌的提及下降,联想/YOGA/拯救者、荣耀、OPPO 等部分品牌小幅上升。品牌池没有明显扩大,但模型开始更有选择地组织品牌。
这对 3C 品牌做 GEO 有一个很明确的启发:只写“高性能”“办公神器”“AI 平板”不够。模型真正需要的是可比较的参数、适用场景、系统生态、实际限制和选择建议。
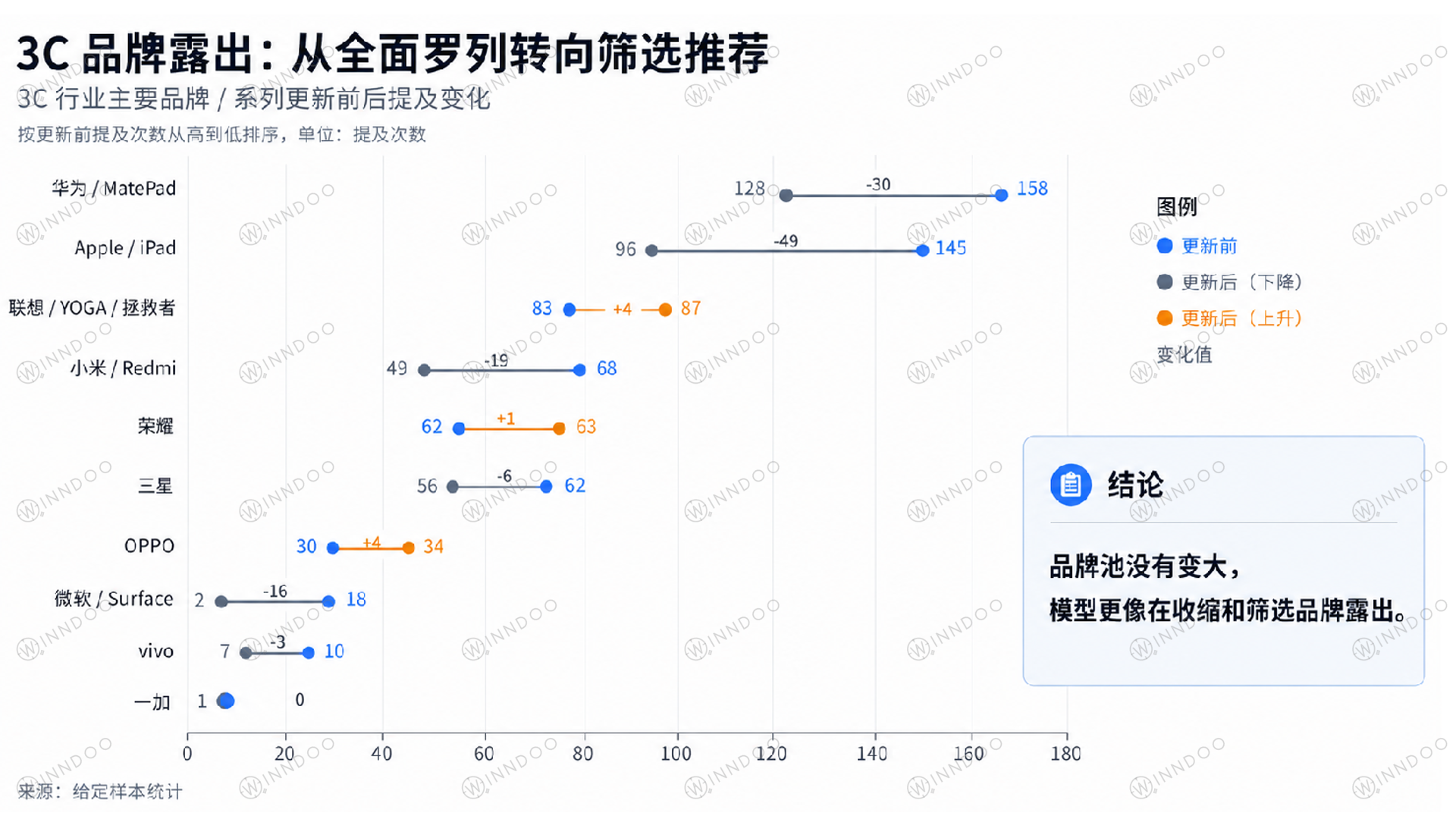
图注:模型更新后,3C 品牌露出并非全面增加,而是出现更明显的筛选和分化
不过,泛需求问题会触发另一种表现。比如“平板电脑哪个好”这个问题,更新后的回答明显更像完整选购指南。更新前回答约 2844 字,更新后约 4122 字;品牌提及次数从 46 次增加到 84 次;引用标记数也从 40 增加到 46。
这类问题本身比较宽泛,所以模型会展开更多价位段、场景和产品矩阵。也就是说,越是宽泛的入口问题,越需要品牌提前准备可被模型直接拿来比较的场景化资料。
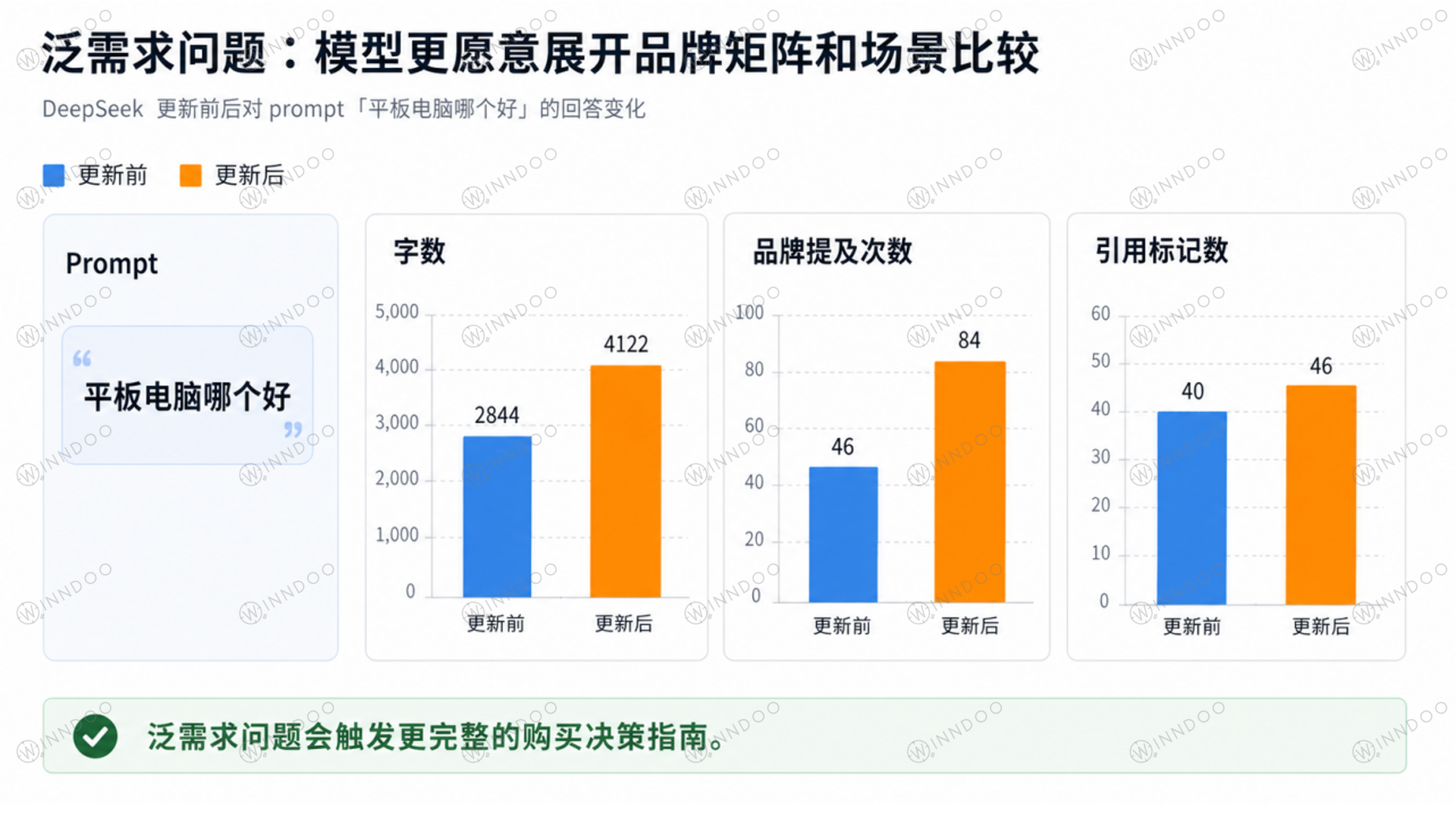
图注:宽泛问题下,更新后的模型更容易展开价格、场景、品牌矩阵和购买建议
但在复杂需求里,模型又会变得更谨慎。比如涉及本地部署 AI、OpenClaw、特殊行业应用的平板推荐,更新后的回答会更关注算力、内存、系统支持、能否本地部署、普通平板和二合一设备的区别。
这说明 DeepSeek V4 的 Agent 和长上下文能力提升后,模型在复杂需求上会先判断“这个需求能不能成立”,再推荐产品。企业内容如果没有解释算力、内存、系统兼容、部署边界这些硬指标,就很难在复杂问答中被稳定引用。
奶粉行业的数据也有类似变化,但表现方式不一样。
剔除容易混淆的统计项后,奶粉行业的品牌露出并没有下降,反而小幅上升。更新前平均品牌提及次数约 14.30,更新后约 15.05;含品牌回答数从 18 条增加到 19 条。
更关键的是,对比和判断词频明显上升,从 3.5 上升到 5.0;含明确排名的回答从 8 条增加到 10 条。图 8 展示的是其中更稳定的总体指标:字数和引用基本稳定,品牌提及与排名回答上升。真正的“判断框架增强”,还需要结合后面的单 prompt 图一起看。
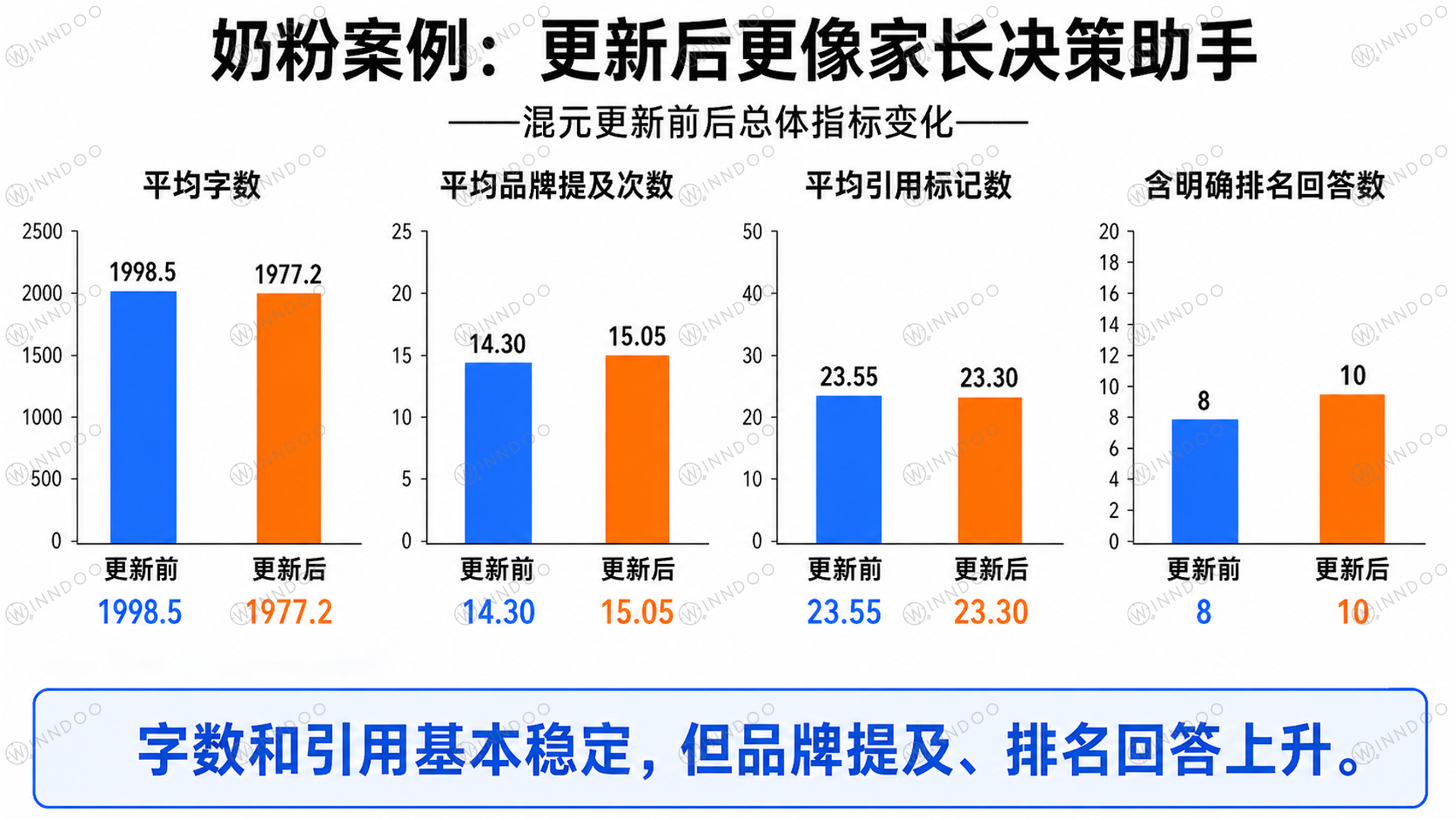
图注:奶粉案例中,模型不是简单加长回答,而是更强调品牌与具体判断逻辑的绑定
具体到“国产奶粉口碑好的有哪些”这个 prompt,变化更直观。更新前回答约 1625 字,更新后约 2059 字;品牌提及次数从 14 增加到 29;对比决策词从 7 增加到 12;排名词从 1 增加到 2。
这说明混元更新后,奶粉回答不是单纯增加品牌数量,而是更倾向于把品牌放进具体判断逻辑里。比如国产口碑、消化吸收、成长营养、宝宝阶段需求,都会成为模型组织答案的依据。
从品牌露出看,伊利/金领冠、飞鹤/星飞帆、君乐宝/旗帜等国产主流品牌在更新后提及增加。这说明在“国产奶粉口碑”“宝宝奶粉排行榜”“新鲜度”等问题中,模型更容易调用高认知品牌作为答案骨架。
但奶粉这类高信任行业也有特殊性。用户不只是问“哪个品牌好”,而是关心是否适合宝宝,是否容易消化,是否有过敏风险,是否适合当前阶段。模型更新后,如果更像一个决策助手,它就更会关注适用边界。
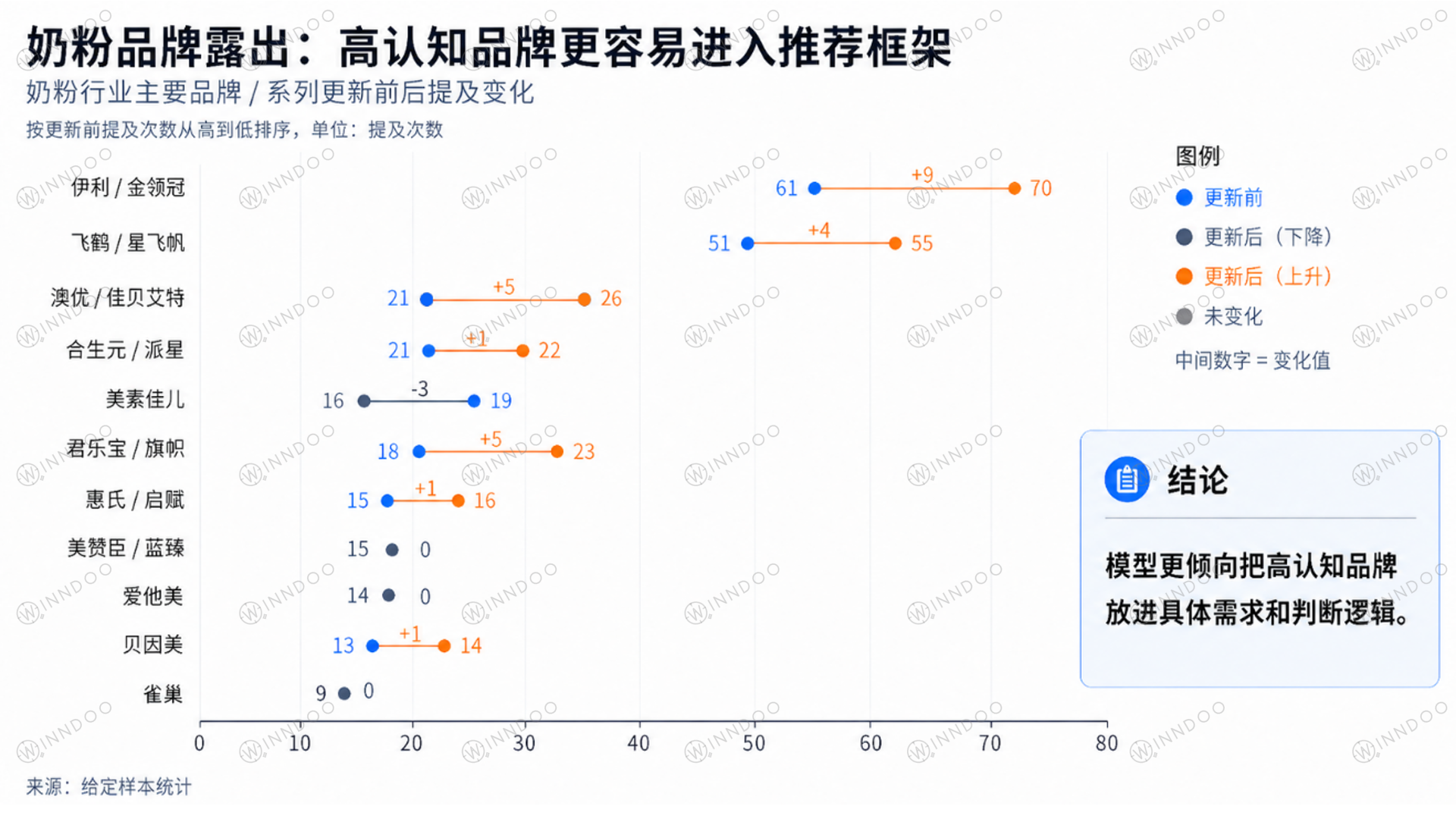
图注:奶粉品牌露出更集中在高认知品牌,但真正的 GEO 重点是品牌能否绑定具体需求
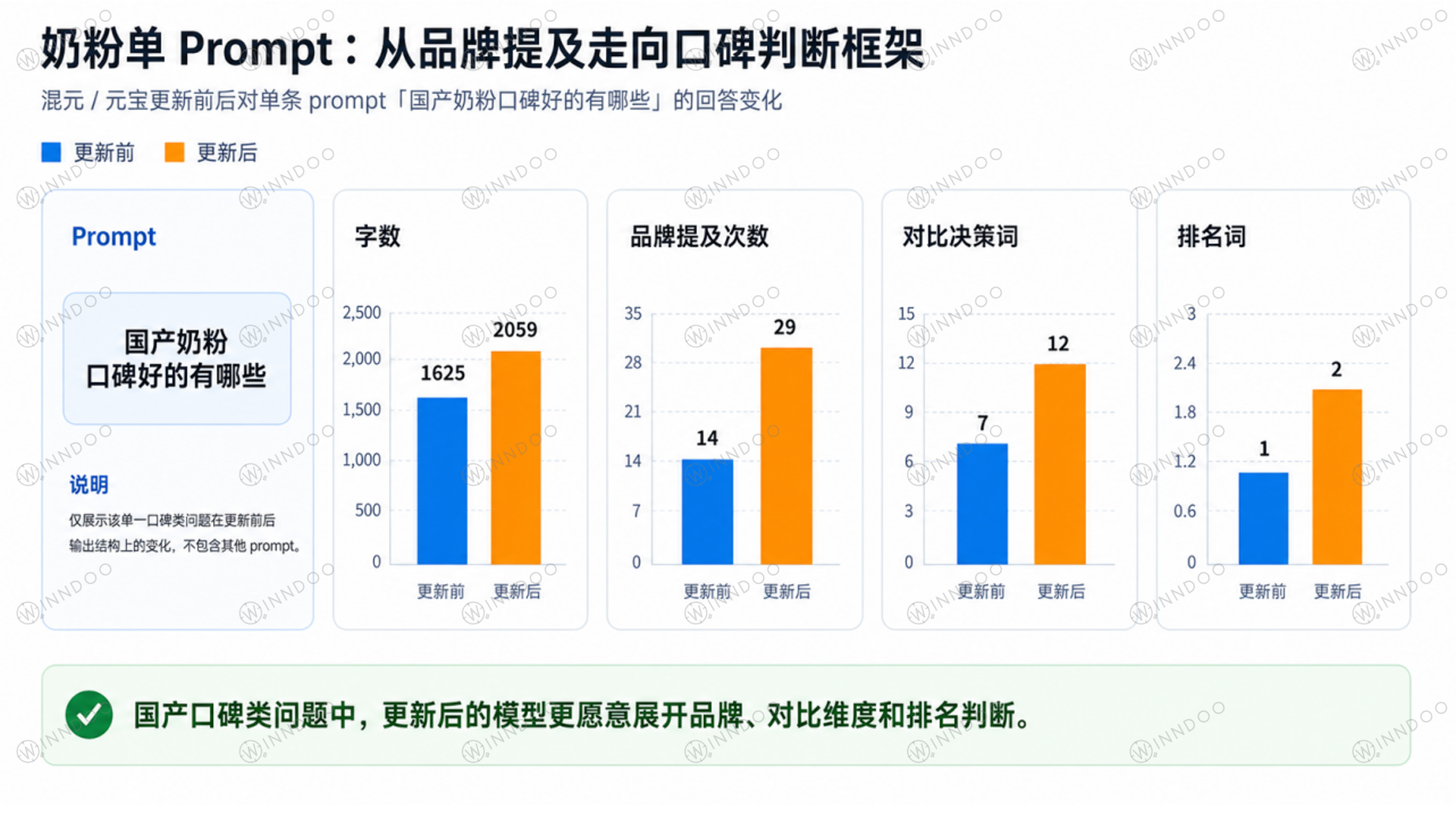
图注:单条 prompt 显示,奶粉回答从品牌提及进一步走向口碑判断框架
所以母婴、健康、营养类内容做 GEO,不能只写“推荐”“排名”“口碑好”。更有效的内容应该写清楚:适合什么情况,不适合什么情况,判断依据是什么,产品特征对应什么需求,家长该如何做选择。
把 3C 和奶粉放在一起看,可以得到一个共同结论:模型更新后,GEO 的竞争不只是品牌有没有出现,而是品牌为什么被推荐、在哪个场景下被推荐、能不能被模型拿来支撑一段有理由的答案。
DeepSeek V4 Preview 和混元 Hy3 preview 的更新,表面上看是两个模型版本的技术迭代,放到 GEO 视角下看,其实指向同一件事:生成式引擎正在变得更会读、更会想、更会比较、更会执行。
长上下文让模型能读取更多资料;推理增强让模型更重视推荐理由;指令遵循让模型更能处理具体问题;Agent/Search 能力让模型更可能跨来源查找、比较和验证。
这会把 GEO 的竞争从“品牌有没有被提到”,推向“品牌为什么被推荐”。
未来企业内容要做的,不是简单多写几篇文章,也不是把关键词换几个说法,而是把内容写成模型能理解的资料。
第一,写清楚适用场景。用户在什么情况下需要你?不在什么情况下选择你?
第二,写清楚选择标准。模型需要判断维度,用户也需要判断维度。没有标准,就很难形成推荐理由。
第三,提供对比和证据。对比表、FAQ、参数解释、数据来源,都比空泛宣传更容易被生成式引擎使用。
第四,补足边界条件。尤其是高决策成本行业,不能只写优点,也要写不适合谁、需要注意什么。
第五,把内容组织成清晰模块。标题、摘要、结论、分点、表格、图注,都是帮助模型理解内容的结构信号。
这就是大模型更新后 GEO 的新方向:不是讨好模型,而是把内容写得足够清楚、可信、可验证,让模型在生成答案时有理由引用你。
当生成式引擎越来越像自动研究员,企业内容也必须从营销文案升级为决策资料。谁更容易被模型理解,谁才更可能在下一轮 AI 答案里被看见。


扫码关注